Pourra-t-on bientôt lire dans les pensées ? Une nouvelle étude décode des images d’activité cérébrale pour en extraire des mots - et du sens

Un scanner d'IRM, une technique d'imagerie similaire à celle utilisée pour cette étude. Illustration. Pexels
Partager un article
Durée de lecture: 10 Min.
Durée de lecture: 10 Min.
Il est de plus en plus réaliste, d’un point de vue technologique, d’imaginer décoder les pensées des humains. Pour la première fois, des neuroscientifiques ont pu « décoder » des données d’imagerie non invasive des cerveaux de trois participants pour reconstruire des suites de mots et le sens global d’histoires que les participants avaient écouté, regardé ou imaginé.
Dans cette nouvelle étude, publiée dans Nature Neuroscience, Alexander Huth et ses collègues, de l’université du Texas, ont réussi à extraire le sens global et ainsi que des phrases, d’images de l’activité du cerveau obtenues par imagerie à résonance magnétique fonctionnelle (ou IRM fonctionnelle).
Décoder le langage
Synthétiser des mots grâce à des signaux cérébraux pourrait être très utiles pour les personnes n’ayant pas accès à la parole à cause de maladies comme les maladies des motoneurones, qui affectent les neurones contrôlant les mouvements volontaires du corps. Ces recherches soulèvent aussi des interrogations sur l’existence de notre vie privée la plus intime, celle de nos pensées.
Les modèles de décodage du langage, ou « décodeurs de la parole », cherchent à utiliser des enregistrements d’activité cérébrale pour en déduire les mots que les sujets entendent, disent ou imaginent.
Jusqu’à présent, les décodeurs de langage avaient seulement été utilisés sur des données obtenues grâce à des dispositifs implantés dans le cerveau, ce qui limitait leur utilité. Et jusqu’ici, les décodeurs utilisant des enregistrements non invasifs de l’activité cérébrale décodaient des mots uniques ou des phrases très brèves, mais n’étaient pas appliqués pour extraire le sens d’un discours continu.
Dans cette nouvelle étude, c’est un signal bien particulier de l’IRM fonctionnelle qui a été exploité : ce signal dépend des flux de sang dans le cerveau et du niveau d’oxygénation du sang.
En se focalisant sur l’activité cérébrale dans les régions du cerveau et dans les réseaux neuronaux qui sont connus pour traiter le langage, les chercheurs ont montré que leur décodeur pouvait être entraîné à reconstruire un discours continu, comprenant des mots spécifiques mais aussi le sens global de phrases plus complètes.
Le décodeur a utilisé les réponses cérébrales de trois participants enregistrées alors que ceux-ci écoutaient des histoires, et il a généré des séquences de mots qui auraient pu produire l’activité cérébrale enregistrée. Ces séquences de mots reproduisaient plutôt bien l’idée générale de l’histoire, et, dans certains cas, incluaient même des mots ou des phrases exacts.
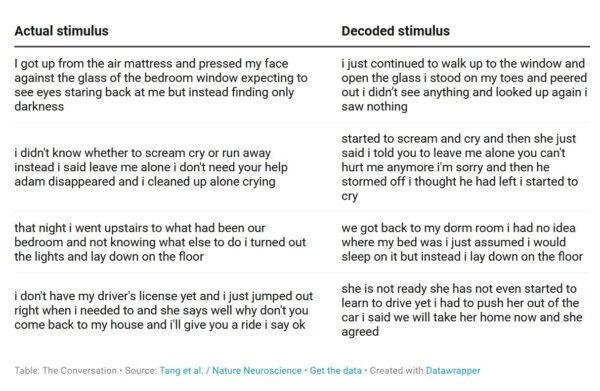
À l’intérieur du scanner d’IRM fonctionelle, les participants ont aussi été amenés à regarder des films muets et à imaginer les histoires correspondantes. Dans les deux cas, le décodeur a été capable de prédire l’essentiel des histoires.
Par exemple, un participant a pensé « Je n’ai pas encoure mon permis de conduire » (I don’t have my driver’s licence yet), et le décodeur a prédit « Elle n’a même pas encore appris à conduire » (She has not even started to learn to drive yet).
De plus, lorsque les participants ont dû écouter activement une histoire en ignorant une seconde histoire diffusée simultanément, le décodeur a seulement pu identifier la première intrigue.
Comment ça marche ?
Tout d’abord, les scientifiques ont demandé aux participants de passer 16 heures dans un scanner IRM fonctionnelle, où ils ont écouté des histoires lues pendant que leurs activités cérébrales étaient enregistrées.
Ces réponses cérébrales ont servi à entraîner un « encodeur », c’est-à-dire un modèle informatique qui prédit comment le cerveau réagit aux mots entendus par le participant. Après cet entraînement, l’encodeur peut prédire avec une bonne précision ce que le cerveau de chaque participant répondrait à l’écoute d’une suite de mots particuliers.
Mais aller dans l’autre direction, c’est-à-dire extraire une suite de mots à partir de l’activité cérébrale, est bien plus difficile.
En effet, le modèle d’encodeur est conçu pour relier des activités cérébrales et des « éléments sémantiques » ou le sens global de mots ou de phrases. Pour y parvenir, le système utilise le modèle de langage « GPT », pour generative pre-trained transformer, le précurseur du GPT-4 actuel. Le décodeur génère ensuite la suite de mots qui aurait pu produire la réponse cérébrale observée.

Pendant ce processus, très gourmand en ressources de calcul, de nombreuses prédictions sont générées une par une, et elles sont classées en fonction de leurs justesses : les prédictions peu adéquates sont éliminées, les plus précises sont conservées. Puis, le mot suivant dans la séquence est prédit, jusqu’à ce que la séquence la plus juste soit déterminée.
Des mots et du sens
La nouvelle étude montre que, pour mener à bien le processus de prédiction, des données provenant de multiples régions du cerveau étaient nécessaires. Ces régions sont diverses mais très spécifiques : il s’agit du réseau prenant en charge la parole, de la région d’association pariétale/temporale/occipitale et du cortex préfrontal.
Une différence majeure entre ce travail et les études précédentes est le type de données utilisées. En effet, la plupart des décodeurs relient des données provenant de régions cérébrales impliquées dans la dernière étape de la formation de la parole, à savoir les mouvements de la bouche et de la langue. Ce décodeur-ci travaille à un autre niveau, sur les idées et la signification des pensées.
Une des limitations des données d’IRM fonctionnelle est leur faible « résolution temporelle ». En effet, le signal d’oxygénation du sang croît et décroît en environ 10 secondes, une période pendant laquelle nous entendons une vingtaine de mots ou plus. Par conséquent, cette technique ne détecte pas de mots individuels mais la signification probable de suites de mots.
On ne panique pas (pas encore)
L’idée que l’on puisse lire dans les pensées soulève naturellement des inquiétudes quant à l’existence de notre vie privée la plus intime, ce qui se passe dans nos têtes. Les chercheurs ont réalisé des expériences additionnelles pour clarifier les capacités de la technique.
Ces expériences montrent qu’il n’y a pas encore à s’inquiéter de ce que nos pensées puissent être lues quand on marche dans la rue, ou si l’on est pas prêt à coopérer.
En effet, un décodeur entraîné sur les données cérébrales d’une personne prédit mal les éléments sémantiques à partir des données cérébrales d’une autre personne. De plus, les participants peuvent compliquer la tâche de décodage en tournant leur attention vers une autre tâche, par exemple nommer des animaux ou raconter une autre histoire.
Le décodeur fonctionne également mal si les participants bougent dans le scanner d’IRM fonctionnelle, car c’est une technique d’imagerie très sensible aux mouvements. La coopération des participants est ici indispensable.
Avec ces contraintes techniques, qui s’ajoutent au besoin d’ordinateurs très puissants pour faire tourner le décodeur, il est très improbable à ce stade que l’on puisse à ce stade décoder les pensées de quelqu’un contre son gré.
Enfin, le décodeur ne marche pour l’instant qu’avec des données obtenues par IRM fonctionnelle, qui est une technique coûteuse et souvent délicate à mettre en œuvre. Le groupe de recherche a l’intention de tester cette méthode avec des données issues d’autres technologies non invasives d’imagerie cérébrale.
Article écrit par Christina Maher, Biomedical Engineer and Neuroscientist, University of Sydney
Cet article est republié à partir de The Conversation sous licence Creative Commons. Lire l’article original.

Articles actuels de l’auteur
08 novembre 2025
Redécouvrir la lumière oubliée du Moyen Âge

29 avril 2024
France-Chine, 60 ans d’ambivalence

31 juillet 2023
Du pétrole sur vos cheveux, quelle bonne idée…







